こんにちは!TechFUL PROでアルバイトをしているPeyjunです!TechFUL PROでは、人工知能やデータサイエンスに関する問題を作成しています。
今回は、昨今の画像分類の分野で注目を集めている、「CLIP」というモデルについて紹介したいと思います。
CLIP
CLIPは、2021年にOpenAIが発表した画像分類の事前学習モデルです。CLIPの大きな特徴の1つに、好きなテキストで画像分類ができるという特徴があります。一般的な画像分類では、画像のカテゴリー数に合わせて定量的に扱うための数値に置き換える、ラベリングという作業が必要であり、訓練時に設定したラベルの範囲でしか分類することができませんでした。しかし、CLIPでは、このラベルを好きな数、好きなテキストに変更して画像分類を行うことが可能となっています。
では、実際にどのようなアルゴリズムでCLIPは事前学習を行っているかについて、特徴ベクトル、表現学習、対照学習というキーワードとともに説明していきたいと思います。
特徴ベクトル
まずは、1つめのキーワードである特徴ベクトルについて説明します。
特徴ベクトルは、文字通り「データの特徴を表すベクトル」です。例えば、象、うさぎ、キリンという3つの動物を (体の大きさ , 鼻の長さ , 首の長さ , 耳の長さ) という4次元の特徴ベクトルで表すと、それぞれ (10,10,3,7) , (2,5,4,10) , (10,6,10,1) という特徴をとらえたベクトルで表現することができます。これが特徴ベクトルであり、この特徴ベクトルで表現される空間を特徴空間といいます。
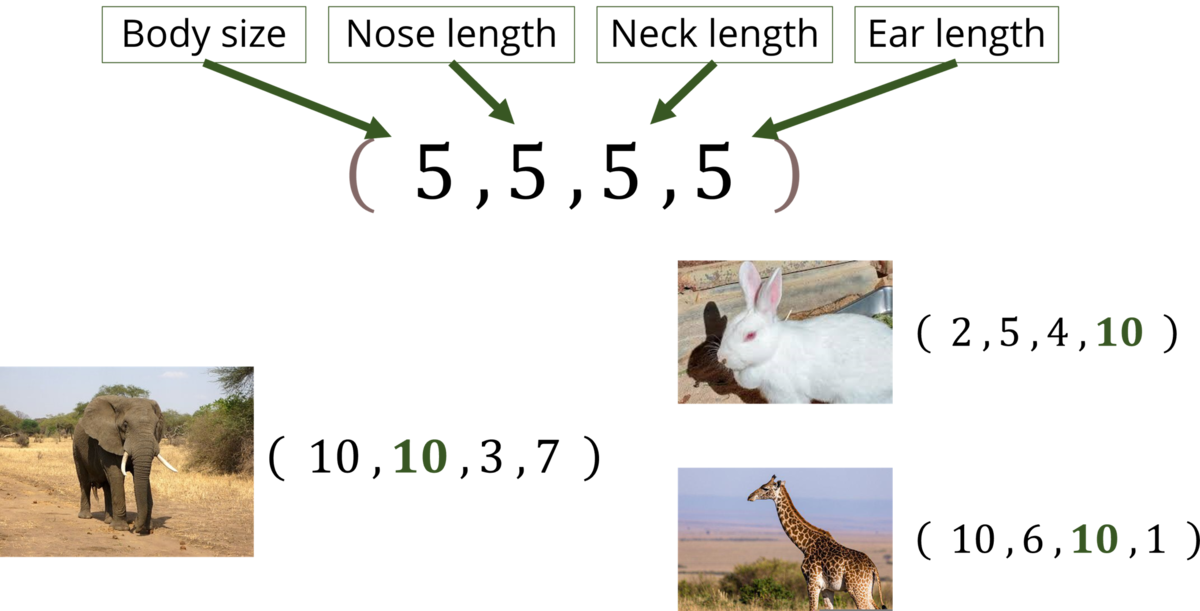
特徴ベクトルは画像分類では非常に有用で、予測精度の向上、計算コスト・学習時間の削減、過学習の抑制などが期待できます。しかし、何千万枚もある画像すべてを手動で特徴ベクトルに変換するのは非常に困難です。そのため、自動で画像を特徴ベクトルに変換するために考えられた方法が表現学習になります。
表現学習
表現学習は、入力されたデータの重要な特徴量を自動で抽出できるようにモデルを学習させる機械学習の手法です。入力データを特徴ベクトルに変換するエンコーダを学習させることで、入力データを適切な特徴ベクトルに機械的に変換することができます。
表現学習の代表的な手法の1つに、オートエンコーダがあります。オートエンコーダは、入力されたデータから重要な特徴量を抽出した後、元の次元に復元するアルゴリズムです。入力されたデータは、エンコーダによって自動で特徴ベクトルに変換されます。訓練時は、入力データと同じデータを復元できるよう、エンコーダとデコーダを学習させていきます。
CLIPでは、イメージエンコーダとテキストエンコーダによって画像とテキストを特徴ベクトルに変換しています。そして、それぞれの特徴ベクトルの類似度を計算して、似ている画像とテキストのペアは似ている特徴ベクトルになるよう、似ていない画像とテキストのペアは似ていない特徴ベクトルになるようエンコーダを学習します。では、具体的にエンコーダをどのように学習させているのでしょうか?CLIPでは、対照学習という手法を用いて学習を行っています。

対照学習
対照学習は、表現学習の代表的な手法の1つです。
- 似ているデータ→似ている特徴ベクトル
- 似ていないデータ→似ていない特徴ベクトル
という変換ができるようにエンコーダを学習させていきます。
具体的には、まずもととなるデータ(Anchor)と、もとのデータと似ているデータ(Positive)、もとのデータと似ていないデータ(Negative)を用意します。そして、特徴空間上で似ているデータの特徴ベクトルは近くなるように、似ていないデータの特徴ベクトルは遠くなるように、エンコーダを学習させます。特徴ベクトル間の距離を求める距離関数は様々ですが、CLIPではコサイン類似度が採用されています。
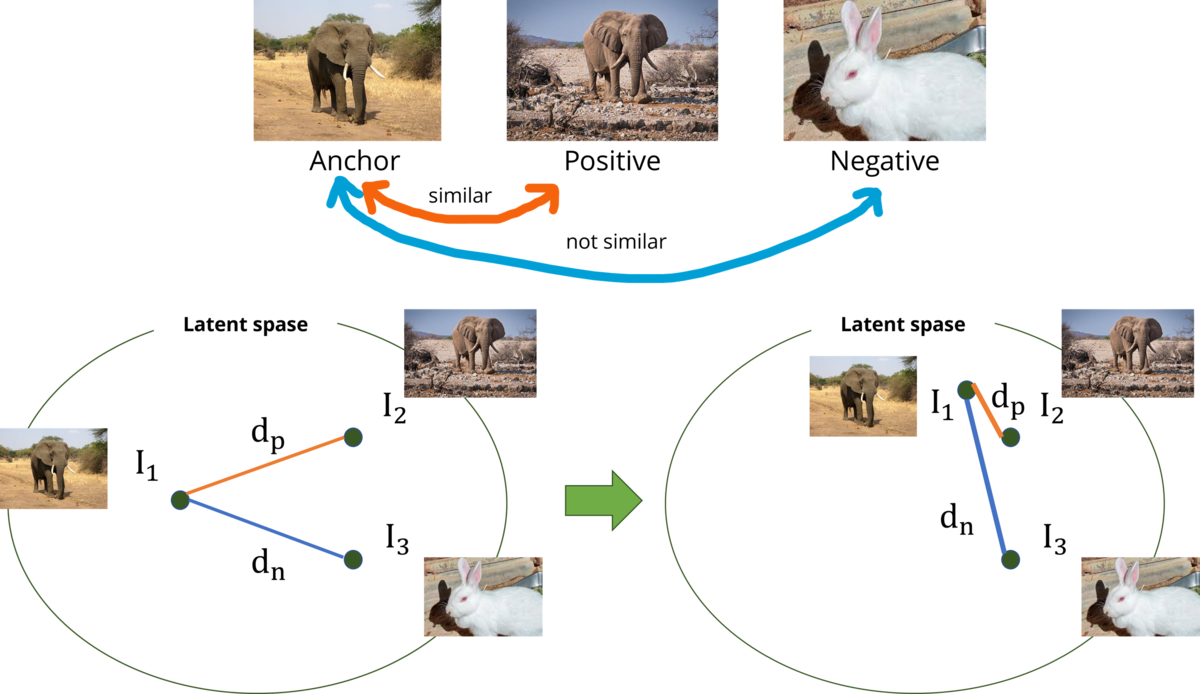
エンコーダを学習させるための損失関数に関しても複数の手法が提案されていますが、今回はTriplet lossという手法についてご紹介します。
Triplet Lossは、αというマージンを表す定数を用意して、似ている特徴ベクトルと似ていない特徴ベクトルが、αだけ離れた距離になるように、学習させるための損失関数です。式は次の通りで、が小さくなるように最適化を行います。
以上が対照学習の概要になります。
CLIPの最適化
ここまでくれば、CLIPの学習の流れを理解することは簡単です。CLIPの学習の流れは、
- 画像とテキストのペアデータを入力する
- エンコーダで特徴ベクトルに変換する
- 画像の特徴ベクトルとテキストの特徴ベクトルのコサイン類似度を計算する
- 対照学習によりエンコーダを学習する
という4つのセクションに分割することができます。
ここではCLIPがどのような手法で対照学習を行っているかについて説明します。
まず、損失関数を計算する過程をpythonによる疑似コードで表すと、次のようになります。
#n - バッチサイズ #I [n, h, w, c] - 画像の入力 #T[n, l] - テキストの入力 #W_i[d_i , d_e] - 線形変換のための行列 #W_t[d_t, d_e] - 線形変換のための行列 #t - 温度パラメータ #エンコーダで特徴ベクトルに変換 I_f = image_encoder(I) #[n, d_i] T_f = text_encoder(T) #[n, d_t] #特徴ベクトル間のコサイン類似度を計算するために次元をそろえて正規化[n, d_e] I_e = l2_normalize(np.dot(I_f, W_i), axis=1) T_e = l2_normalize(np.dot(T_f, W_t), axis=1) #コサイン類似度を計算[n, n] logits = np.dot(I_e, T_e.T) * np.exp(t) #損失関数の計算(symmetric loss function) labels = np.arange(n) loss_i = cross_entropy_loss(logits, labels, axis=0) loss_t = cross_entropy_loss(logits, labels, axis=1) loss = (loss_i + loss_t)/2
画像とテキストの特徴ベクトル間のコサイン類似度を計算することで、画像とテキストの距離が計算された行列logitsが形成されます。例えば、logitsの3行目2列目の$I_3\cdot T_2$では、画像$I_3$とテキスト$T_2$の特徴ベクトルのコサイン類似度が計算されています。
そして、画像の損失(loss_i)は、似ているデータのペアであるlogitsの対角要素を正解のカテゴリーとして、logitsの行方向にクロスエントロピーロスを計算します。またテキストの損失(loss_t)は、こちらもlogitsの対角要素を正解のカテゴリーとして、図の列方向にクロスエントロピーロスを計算します。
そしてloss_iとloss_tの平均$(loss_i+loss_t)/2$が最終的な損失関数となります。
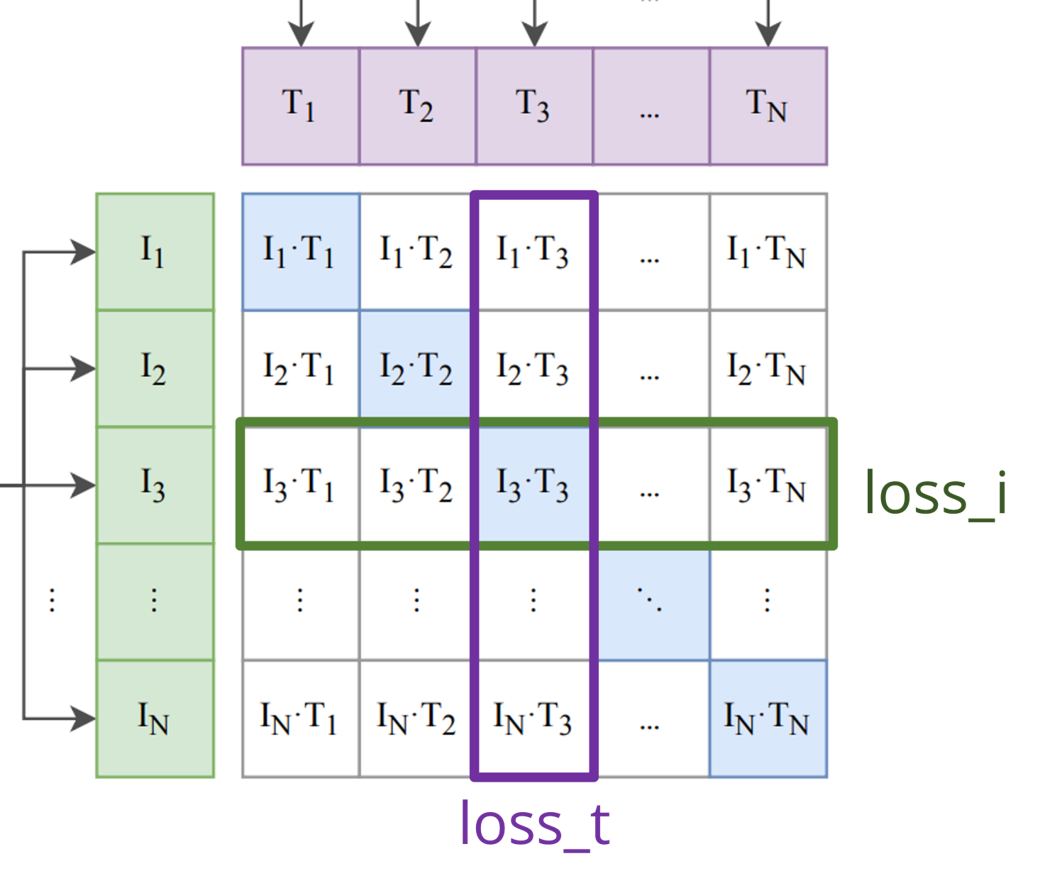
このような損失関数を設定することによって、logitsの対角要素(Positive)のコサイン類似度は大きく、その他の要素(Negative)のコサイン類似度が小さくなるように最適化されます。そして、似ている画像とテキストは似ている特徴ベクトルになるように、似ていない画像とテキストは似ていない特徴ベクトルになるように、エンコーダが学習されます。その結果、画像とテキストの類似度が計算できるようになります。
以上がCLIPのアルゴリズムになります。最後にCLIPを使った簡単な実験を行います。
実験
1枚の画像を用意して、様々なテキストで分類してみました。まず、ネコがバスケットボールをしている画像を用意しました。次に、動物、スポーツ、形容詞という3つのジャンルそれぞれに、私が考えた5つのテキストを設定しました。そして、学習済みのCLIPを用いて、5つのテキストと画像の類似度を計算しました。
pythonコードと結果は以下のようになりました。
from google.colab import drive drive.mount('/content/drive') !pip install ftfy regex tqdm !pip install git+https://github.com/openai/CLIP.git import torch import clip import matplotlib.pyplot as plt from PIL import Image device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-B/32", device=device) texts_en = ["A cat","A dog","A rabbit","A elephant","A fuman"] original_image = Image.open("image_dir/image_1.png") image = preprocess(original_image).unsqueeze(0).to(device) plt.figure() plt.imshow(original_image) plt.show() text = clip.tokenize(texts_en).to(device) with torch.no_grad(): image_features = model.encode_image(image) text_features = model.encode_text(text) logits_per_image, logits_per_text = model(image, text) probs = logits_per_image.softmax(dim=-1).cpu().numpy() for i,text in enumerate(texts_en): print(text,":",round(probs[0,i]*100,2),"%")

悪くない結果ですね!
まとめ
今回はCLIPという画像分類のモデルを紹介させていただきました。汎化性能が非常に高く、様々なタスクに応用されています。興味のある方はぜひ調べてみてください!
参考
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
[2] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–
1607. PMLR, 2020.
[3] J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang, J. Philbin, B. Chen, and Y. Wu. "Learning Fine-grained Image Similarity with Deep Ranking." In CVPR, 2014.
[4] 【論文解説】自然言語処理と画像処理の融合 – OpenAI 『CLIP』を理解する | 楽しみながら理解するAI・機械学習入門